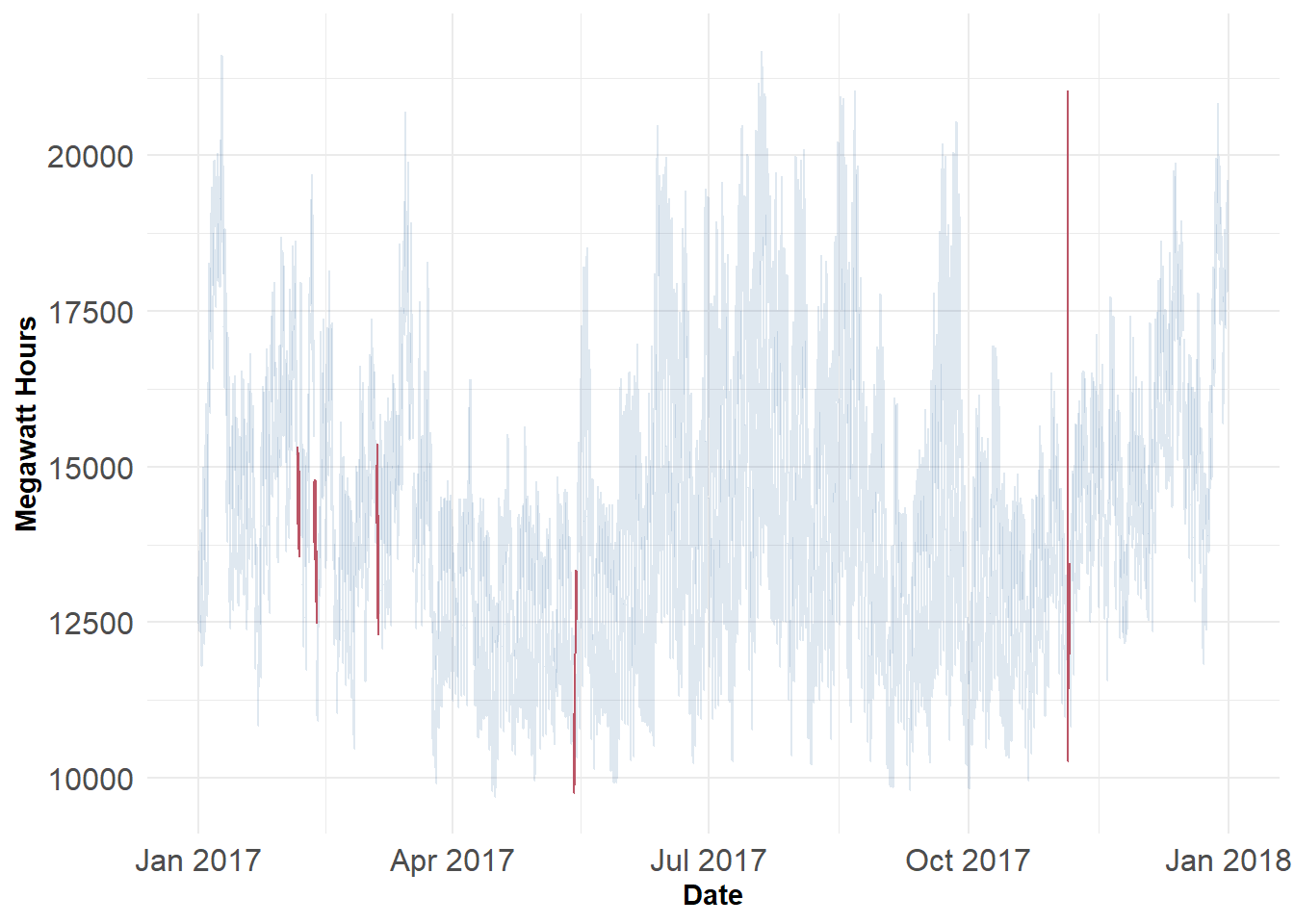
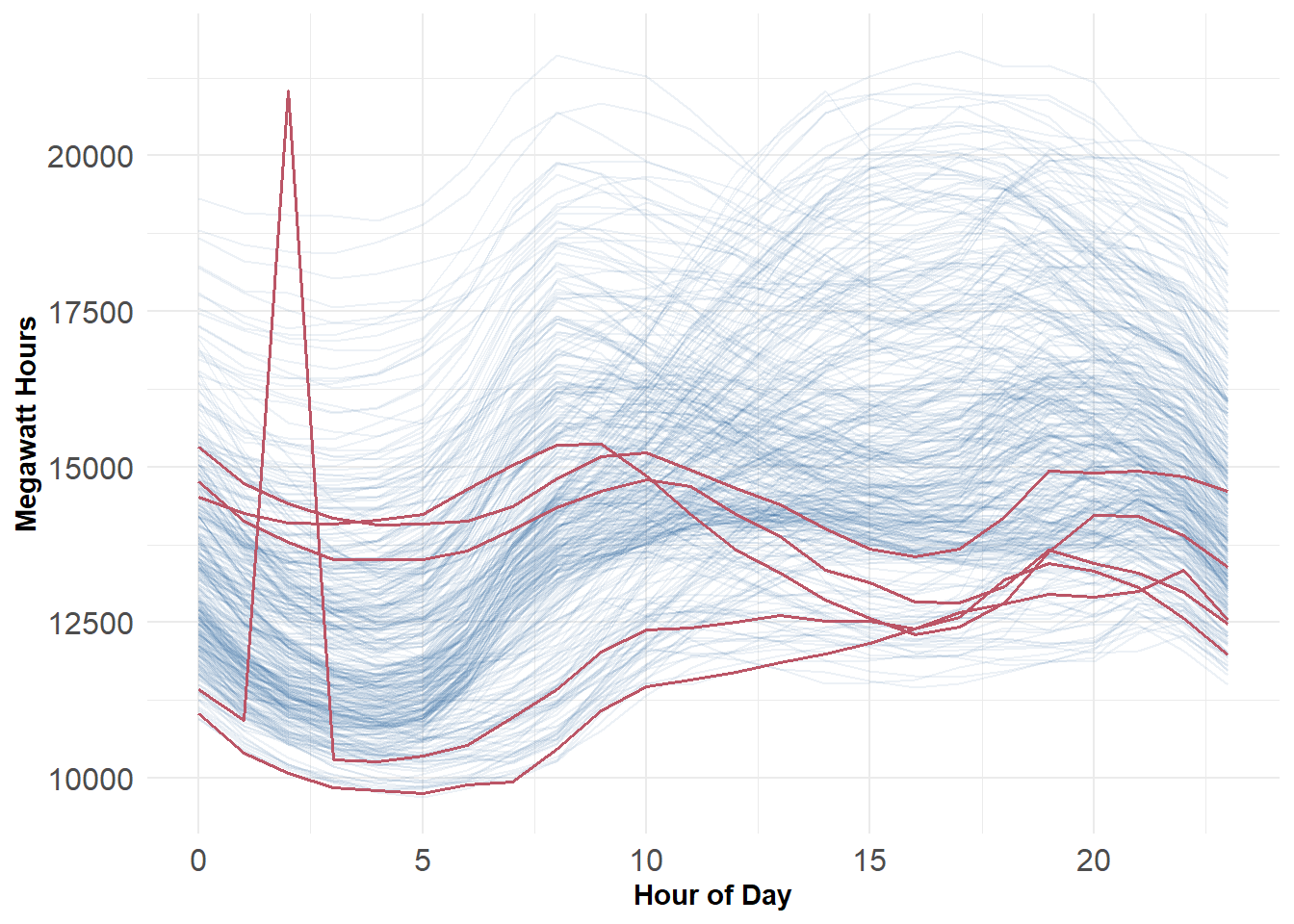
Rows: 364
Columns: 13
$ x_acf1 <dbl> 0.8139510, 0.9318718, 0.9123398, 0.9173901,…
$ x_acf10 <dbl> 1.771656, 2.081091, 1.868137, 1.889912, 1.7…
$ diff1_acf1 <dbl> 0.6284980, 0.6181949, 0.6534759, 0.6194560,…
$ diff1_acf10 <dbl> 1.4141518, 0.7771648, 0.6910469, 1.0491669,…
$ diff2_acf1 <dbl> 0.3426413, 0.2082615, 0.3164917, 0.2786098,…
$ diff2_acf10 <dbl> 0.5009215, 0.2550913, 0.4214296, 0.2577332,…
$ trend <dbl> 0.7256036, 0.9374949, 0.9377550, 0.9478148,…
$ spike <dbl> 1.946527e-04, 4.715699e-06, 6.706533e-06, 4…
$ linearity <dbl> 1.8002798, 3.6310069, 3.3908752, 4.1128389,…
$ curvature <dbl> 0.4988011, -1.2265007, -2.0788821, -0.66100…
$ e_acf1 <dbl> 0.6719203, 0.6507832, 0.6513875, 0.6636410,…
$ e_acf10 <dbl> 1.4588480, 1.0862781, 0.9523931, 1.1326925,…
$ entropy <dbl> 0.3585884, 0.5225069, 0.4962494, 0.3090901,…